
At ISC’23, Intel details competitive performance for diverse HPC and AI workloads, from memory-bound to generative AI, and introduces new science LLM initiative to democratize AI.
NEWS HIGHLIGHTS
- Intel’s broad portfolio of HPC and AI products provides competitive performance, with Intel® Data Center GPU Max Series 1550 showing an average speedup of 30% over Nvidia H100 on a wide range of scientific workloads.1
- Product roadmap updates highlight Granite Rapids, a next-generation CPU to address memory bandwidth demands, and Falcon Shores GPU to meet an expanding, diverse set of workloads for HPC and AI.
- Argonne National Laboratory and Intel announce full Aurora specifications, system momentum and international initiative with Hewlett Packard Enterprise (HPE) and partners to bring the power of generative AI and large language models (LLM) to science and society.
- Enhanced oneAPI and AI tools help developers speed up HPC and AI workloads and enhance code portability across multiple architectures.
At the ISC High Performance Conference, Intel showcased leadership performance for high performance computing (HPC) and artificial intelligence (AI) workloads; shared its portfolio of future HPC and AI products, unified by the oneAPI open programming model; and announced an ambitious international effort to use the Aurora supercomputer to develop generative AI models for science and society.
This press release features multimedia. View the full release here: https://www.businesswire.com/news/home/20230522005289/en/
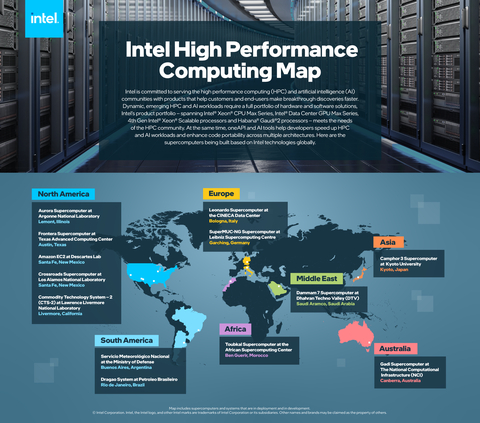
Intel is committed to serving the high performance computing (HPC) and artificial intelligence (AI) communities with products that help customers and end-users make breakthrough discoveries faster. Intel’s product portfolio – spanning Intel® Xeon® CPU Max Series, Intel® Data Center GPU Max Series, 4th Gen Intel® Xeon® Scalable processors and Habana® Gaudi®2 processors – meets the needs of the HPC community. At the same time, oneAPI and AI tools help developers speed up HPC and AI workloads and enhance code portability across multiple architectures. (Credit: Intel Corporation)
More: International Supercomputing Conference 2023 (Quote Sheet)
“Intel is committed to serving the HPC and AI community with products that help customers and end-users make breakthrough discoveries faster,” said Jeff McVeigh, Intel corporate vice president and general manager of the Super Compute Group. “Our product portfolio spanning Intel® Xeon® CPU Max Series, Intel® Data Center GPU Max Series, 4th Generation Intel® Xeon® Scalable Processors and Habana® Gaudi®2 are outperforming the competition on a variety of workloads, offering energy and total cost of ownership advantages, democratizing AI and providing choice, openness and flexibility.”
Hardware Performance at Scale
At the Intel special presentation, McVeigh highlighted the latest competitive performance results across the full breadth of hardware and shared strong momentum with customers.
- The Intel® Data Center GPU Max Series outperforms Nvidia H100 PCIe card by an average of 30% on diverse workloads1, while independent software vendor Ansys shows a 50% speedup for the Max Series GPU over H100 on AI-accelerated HPC applications.2
- The Xeon Max Series CPU, the only x86 processor with high bandwidth memory, exhibits a 65% improvement over AMD’s Genoa processor on the High Performance Conjugate Gradients (HPCG) benchmark1, using less power. High memory bandwidth has been noted as among the most desired features for HPC customers.3
- 4th Gen Intel Xeon Scalable processors – the most widely used in HPC – deliver a 50% average speedup over AMD’s Milan4, and energy company BP’s newest 4th Gen Xeon HPC cluster provides an 8x increase in performance over its previous-generation processors with improved energy efficiency.2
- The Gaudi2 deep learning accelerator performs competitively on deep learning training and inference, with up to 2.4x faster performance than Nvidia A100.1
Customers have recently announced new installations with Intel 4th Gen Xeon and Max Series processors:
- Kyoto University is deploying 4th Gen Xeon for Laurel 3 and Cinnamon 3, and Xeon Max Series processors for Camphor 3.
- Cineca deployed Leonardo with 4th Gen Intel Xeon processors.
- University of Rochester - Laboratory for Laser Energetics is deploying a cluster with 4th Gen Xeon processors.
- Servicio Meteorológico Nacional de Argentina will deploy a system with both Max Series CPUs and GPUs.
Additionally, the Cambridge Open Zettascale Lab at the University of Cambridge has deployed the first Max GPU testbed in the United Kingdom and is seeing positive early results on molecular dynamics and biological imaging applications. Also, RIKEN announced a memorandum of understanding (MoU) with Intel aimed at accelerating joint research and development in the field of advanced computing technologies, such as artificial intelligence, high performance computing and quantum computing. As part of the MoU, RIKEN will also engage with Intel Foundry Services to create prototypes of these new solutions.
Competitive Processors for Every Workload
Dynamic, emerging HPC and AI workloads require a full portfolio of hardware and software solutions. McVeigh provided an overview of Intel’s data center offerings that deliver many choices and solutions for the HPC community, helping to democratize AI.
In his presentation, McVeigh introduced Intel’s next-generation CPUs to meet high memory bandwidth demands. Intel led the ecosystem to develop a new type of DIMM – Multiplexer Combined Ranks (MCR) – for Granite Rapids. MCR achieves speeds of 8,800 megatransfers per second based on DDR5 and greater than 1.5 terabytes/second (TB/s) of memory bandwidth capability in a two-socket system. This boost in memory bandwidth is critical for feeding the fast-growing core counts of modern CPUs and enabling efficiency and flexibility.
Intel also disclosed a new, AI-optimized x8 Max Series GPU-based subsystem from Supermicro, designed to accelerate deep learning training. In addition to access via Intel® Developer Cloud beta5 later this year, multiple OEMs will offer solutions with Max Series GPUs x4 and x8 OAM subsystems and PCIe cards, which will be available in the summer.
Intel’s next-generation Max Series GPU, Falcon Shores, will give customers the flexibility to implement system-level CPU and discrete GPU combinations for the new and fast-changing workloads of the future. Falcon Shores is based on a modular, tile-based architecture and will:
- Support HPC and AI data types, from FP64 to BF16 to FP8.
- Enable up to 288GB of HBM3 memory with up to 9.8TB/s total bandwidth and vastly improved high-speed I/O.
- Empower the CXL programming model.
- Present a unified GPU programming interface through oneAPI.
Generative AI for Science
Argonne National Laboratory, in collaboration with Intel and HPE, announced plans to create a series of generative AI models for the scientific research community.
“The project aims to leverage the full potential of the Aurora supercomputer to produce a resource that can be used for downstream science at the Department of Energy labs and in collaboration with others,” said Rick Stevens, Argonne associate laboratory director.
These generative AI models for science will be trained on general text, code, scientific texts and structured scientific data from biology, chemistry, materials science, physics, medicine and other sources.
The resulting models (with as many as 1 trillion parameters) will be used in a variety of scientific applications, from the design of molecules and materials to the synthesis of knowledge across millions of sources to suggest new and interesting experiments in systems biology, polymer chemistry and energy materials, climate science and cosmology. The model will also be used to accelerate the identification of biological processes related to cancer and other diseases and suggest targets for drug design.
Argonne is spearheading an international collaboration to advance the project, including Intel; HPE; Department of Energy laboratories; U.S. and international universities; nonprofits; and international partners, such as RIKEN.
Additionally, Intel and Argonne National Laboratory highlighted installation progress, system specs and early performance results for Aurora:
- Intel has completed the physical delivery of more than 10,000 blades for the Aurora supercomputer.
- Aurora’s full system, built using HPE Cray EX supercomputers, will have 63,744 GPUs and 21,248 CPUs and 1,024 DAOS storage nodes. And it will utilize the HPE Slingshot high-performance Ethernet network.
- Early results show leading performance on real-world science and engineering workloads, with up to 2x performance over AMD MI250 GPUs, 20% improvement over H100 on the QMCPACK quantum mechanical application, and near linear scaling up to hundreds of nodes.2
Aurora is expected to offer more than 2 exaflops of peak double-precision compute performance when launched this year.
Productive, Open Accelerated Computing Through oneAPI
Worldwide, about 90% of all developers benefit from or use software developed for or optimized by Intel.6 Since the oneAPI programming model launched in 2020, developers have demonstrated oneAPI on diverse CPU, GPU, FPGA and AI silicon from multiple hardware providers, addressing the challenges of single-vendor accelerated programming models. The latest Intel oneAPI tools deliver speedups for HPC applications with OpenMP GPU offload, extend support for OpenMP and Fortran, and accelerate AI and deep learning through optimized frameworks, including TensorFlow and PyTorch, and AI tools, enabling orders of magnitude performance improvements.
oneAPI makes multiarchitecture programming easier for programmers through oneAPI’s SYCL implementation, oneAPI plug-ins for Nvidia and AMD processors developed by Codeplay, and the Intel® DPC++ Compatibility Tool (based on open source SYCLomatic) that migrates code from CUDA to SYCL and C++ where 90-95% of code typically migrates automatically.7 The resulting SYCL code shows comparable performance with the same code running on Nvidia- and AMD-native systems languages. Data shows SYCL code for the DPEcho astrophysics application running on the Max Series GPU outperforms the same CUDA code on Nvidia H100 by 48%.1
The broader ecosystem is embracing SYCL, as well. Eviden, an Atos business, announced CEPP one+ with Intel, an HPC/AI Code modernization service based on Eviden’s Center of Excellence in Performance Programming (CEPP). CEPP one+ will focus on the adoption of SYCL and OpenMP, preparing the community for a heterogeneous computing landscape while providing freedom of choice in hardware through open standards.
About Intel
Intel (Nasdaq: INTC) is an industry leader, creating world-changing technology that enables global progress and enriches lives. Inspired by Moore’s Law, we continuously work to advance the design and manufacturing of semiconductors to help address our customers’ greatest challenges. By embedding intelligence in the cloud, network, edge and every kind of computing device, we unleash the potential of data to transform business and society for the better. To learn more about Intel’s innovations, go to newsroom.intel.com and intel.com.
Disclaimers and configuration:
1 Visit the International Supercomputing Conference (ISC’23) page on intel.com/performanceindex for workloads and configurations. Results may vary.
2 Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
3 Hyperion Research HPC Market Update, Nov. 2022.
4 Intel® Xeon® 8480+ has 1.5x higher geomean HPC performance across 27 benchmarks and applications than AMD EPYC 7763. Results may vary.
5 The Intel Developer Cloud beta is currently available to select prequalified customers.
6 According to Intel estimates.
7 Intel estimates as of March 2023. Based on measurements on a set of 85 HPC benchmarks and samples, with examples like Rodinia, SHOC, PENNANT. Results may vary.
Performance varies by use, configuration and other factors. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. No product or component can be absolutely secure.
Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
Statements in this document that refer to future plans or expectations are forward-looking statements. These statements are based on current expectations and involve many risks and uncertainties that could cause actual results to differ materially from those expressed or implied in such statements. For more information on the factors that could cause actual results to differ materially, see our most recent earnings release and SEC filings at www.intc.com.
© Intel Corporation. Intel, the Intel logo and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
View source version on businesswire.com: https://www.businesswire.com/news/home/20230522005289/en/
Contacts
Bats Jafferji
1-603-809-5145
bats.jafferji@intel.com




